March: RL Pipeline Optimization & Control Strategy Redesign
Work Carried Out
In March, I focused on improving the stability and efficiency of the reinforcement learning (RL) pipeline. During the initial phase, I debugged and tested the custom RL environment, followed by optimizing training performance by reducing reset times and improving overall efficiency. Several test training runs were conducted to evaluate system behavior.
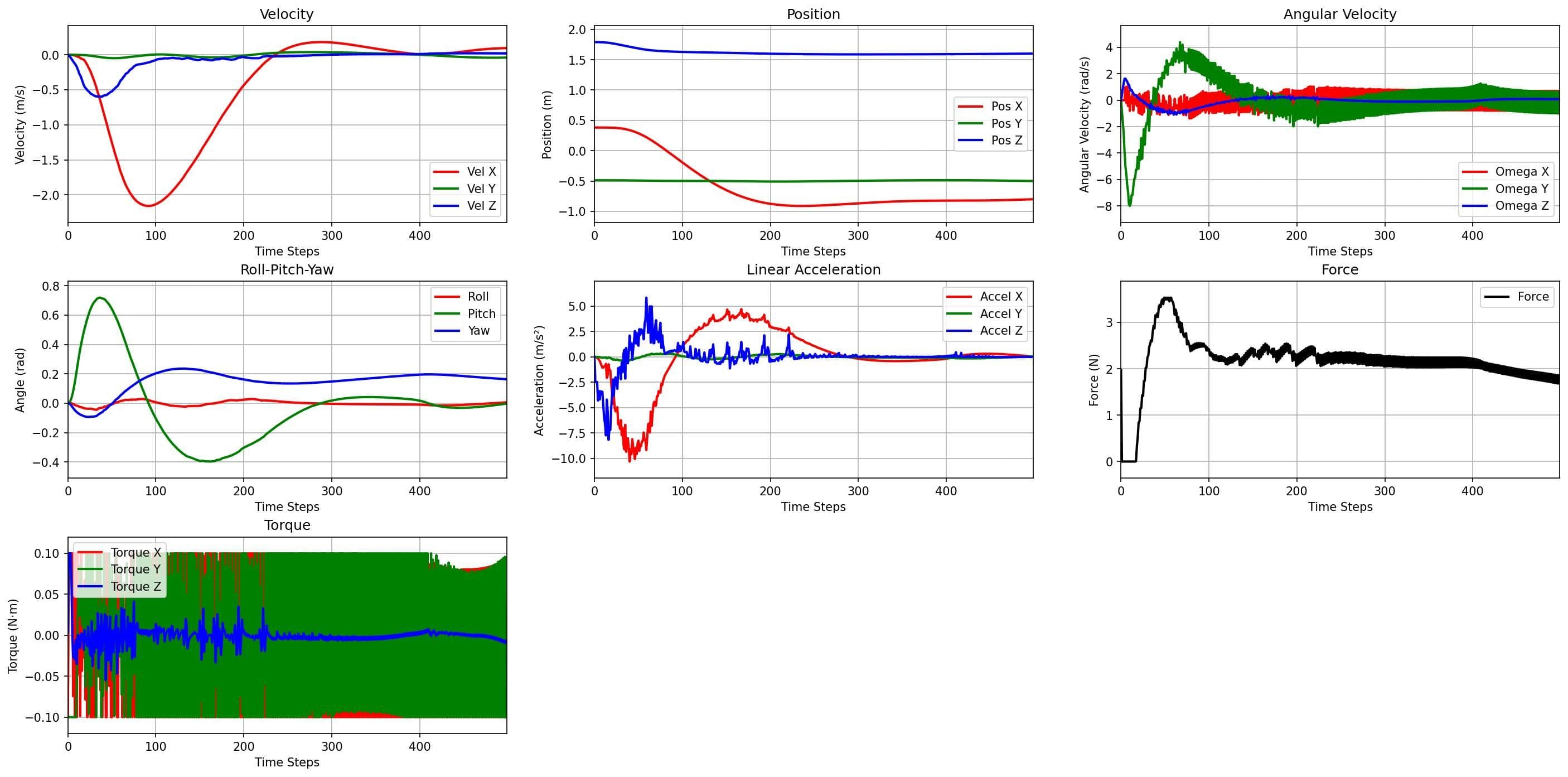
I also refined the reward function through reward shaping and reviewed relevant RL literature to guide improvements. Initial training sessions were carried out with hyperparameter tuning to assess performance and learning stability.
Problems Encountered
A key limitation was identified in the control strategy. The residual torque-based approach was ineffective, as RL signals could not match the high update rate (1 kHz) of the PX4 Autopilot rate controller.
Solutions / How Issues Were Addressed
To resolve this, the control strategy was redesigned to inject residual angular rate commands at an earlier stage in the PX4 control stack. This improved compatibility between the RL controller and the flight control system, leading to more effective control behavior.